画像分析体验总结:
整体分为两个部分:
标签管理:
1 | 1、配置对应的数据源,将数据源表定义为“实体”,字段定义为标签 |
群体画像:
1 | 更主要的是关注业务上每个字段的筛选,过滤条件,组合出满足业务要求的分析场景。 |
体验前后的差异对比:
没有使用阿里产品前的实现方式:
1 | 每一次业务规则的调整,都需要修改代码,重新执行,才能得到最新的结果 |
使用阿里产品的实现方式:
1 | 只需要在界面上重新配置过滤规则,然后执行筛选,就能得到最新的结果,并能通过多种图表方式直观的呈现出来。 |
特点:
省去了重新修改代码的环节,从业务的角度调整规则即可实现画像分析。随着多种图表展现形式对结果的反馈,可以不断的完善规则,从而提高了画像分析的准确性和时效性。
适用场景:
基础的标签(指标)数据生成好后,提供给业务人员,进行业务角度的数据分析使用,可以快速的将群体方案直接发布为API对外提供
目标与操作过程:
本次目标:
1、尝试用这份数据找分析出,高压力中年油腻男,单身带娃,无父母补贴,低学历,高年龄
2、尝试用这份数据找分析出,单身女强人,单身无娃,有父母补贴,高学历,中低年龄
前提条件 – 数据准备:
一、准备数据源:
1、建立数据表:
1 | CREATE TABLE `test_data_quotient_person_info` ( |
2、配置数据:
二、配置dataworks数据同步:
1、按照数据源的方式建表,然后选择对应的同步信息:
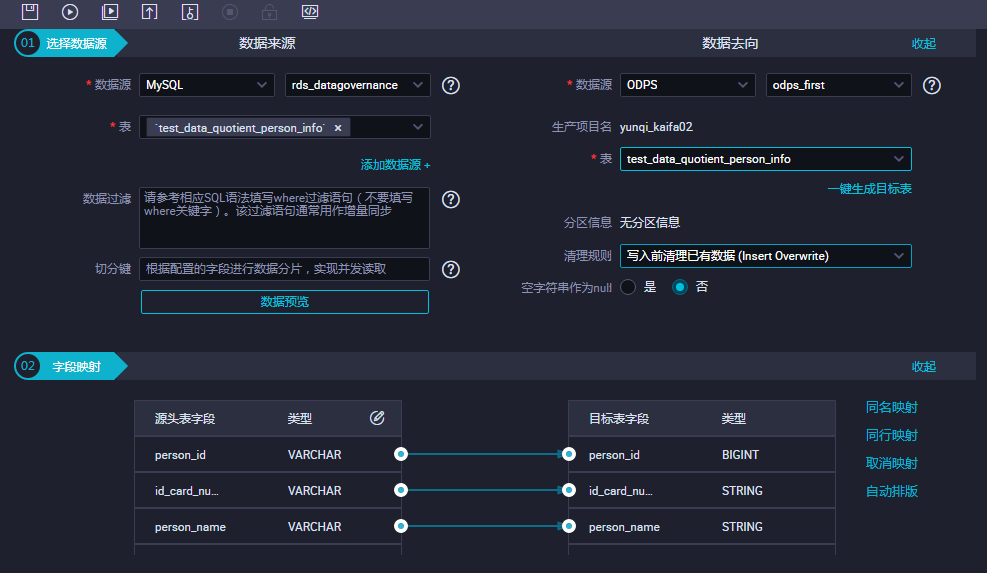
2、配置调度:
此处省略
画像分析 – 标签管理
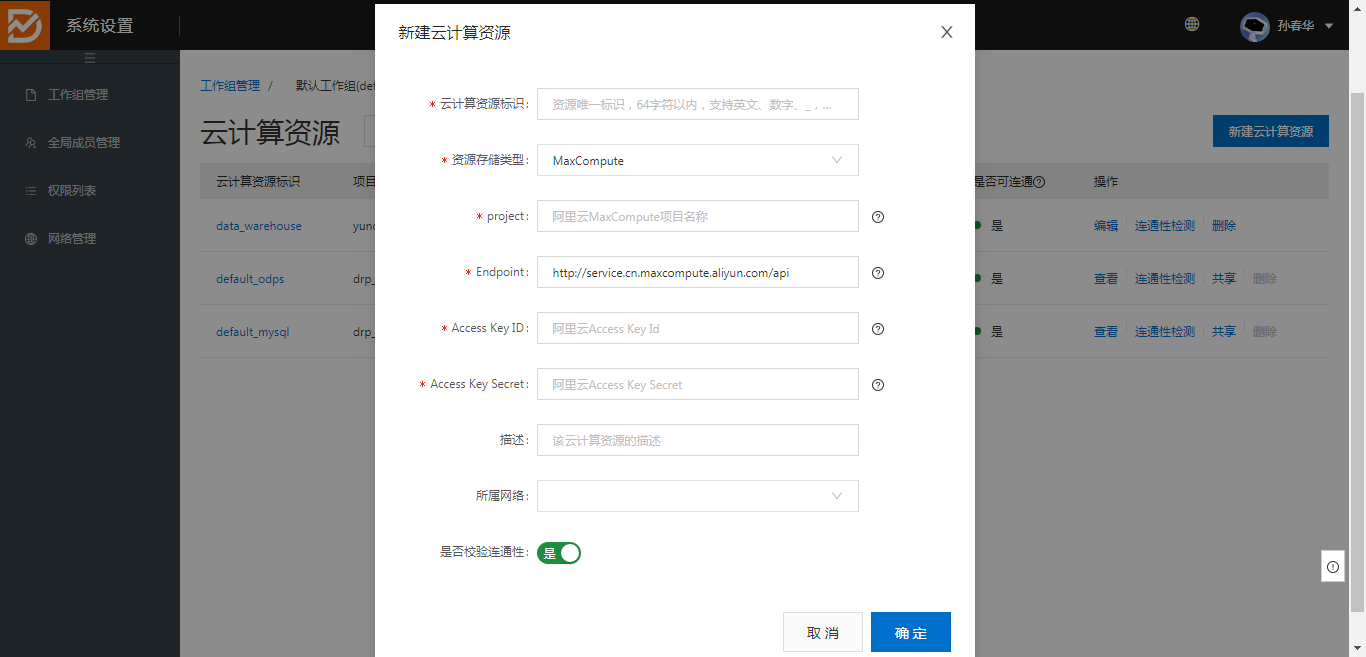
三、云计算资源:
1、配置外部的云计算资源,类似于“数据集成”中的数据源管理。
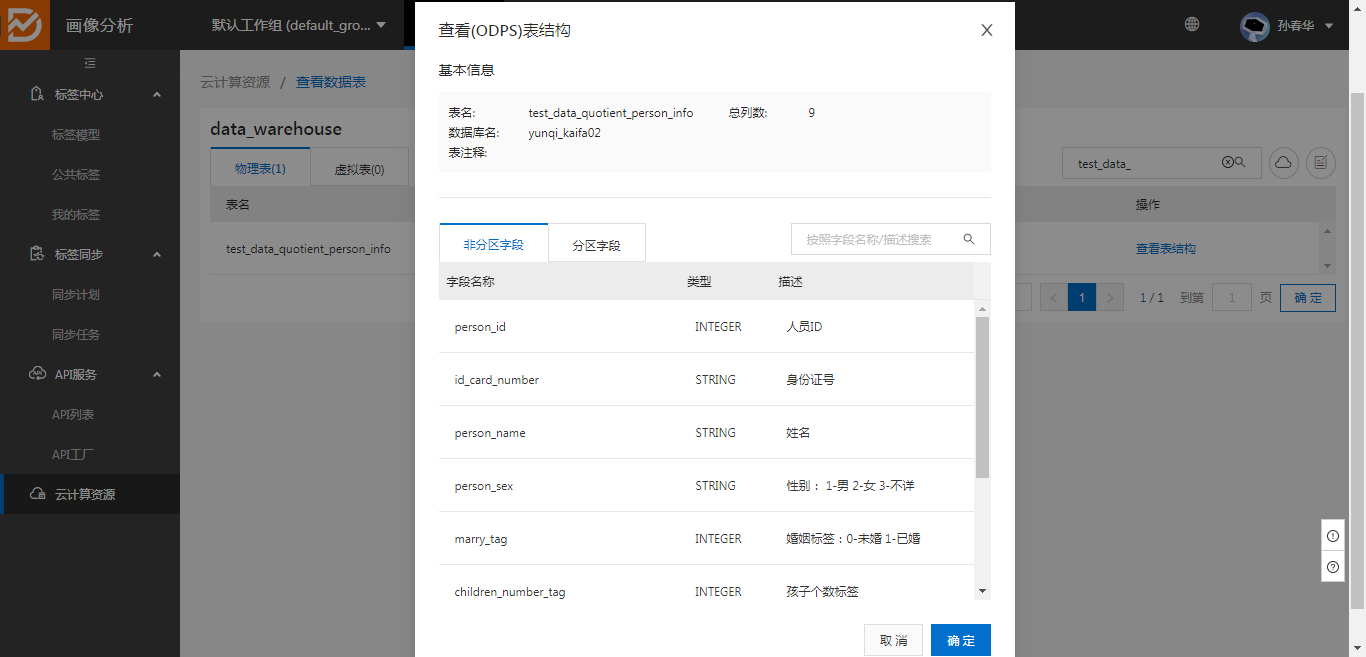
2、配置好外部云计算资源后可以查看对应的库表信息:
四、标签中心:
1、新建标签模型实体
1 | ** 关系模型还未体验 ** |
2、实体绑定标签数据表
绑定表的时候需要先”更新缓存表“更新成功后,才能看到新加入的源数据表。
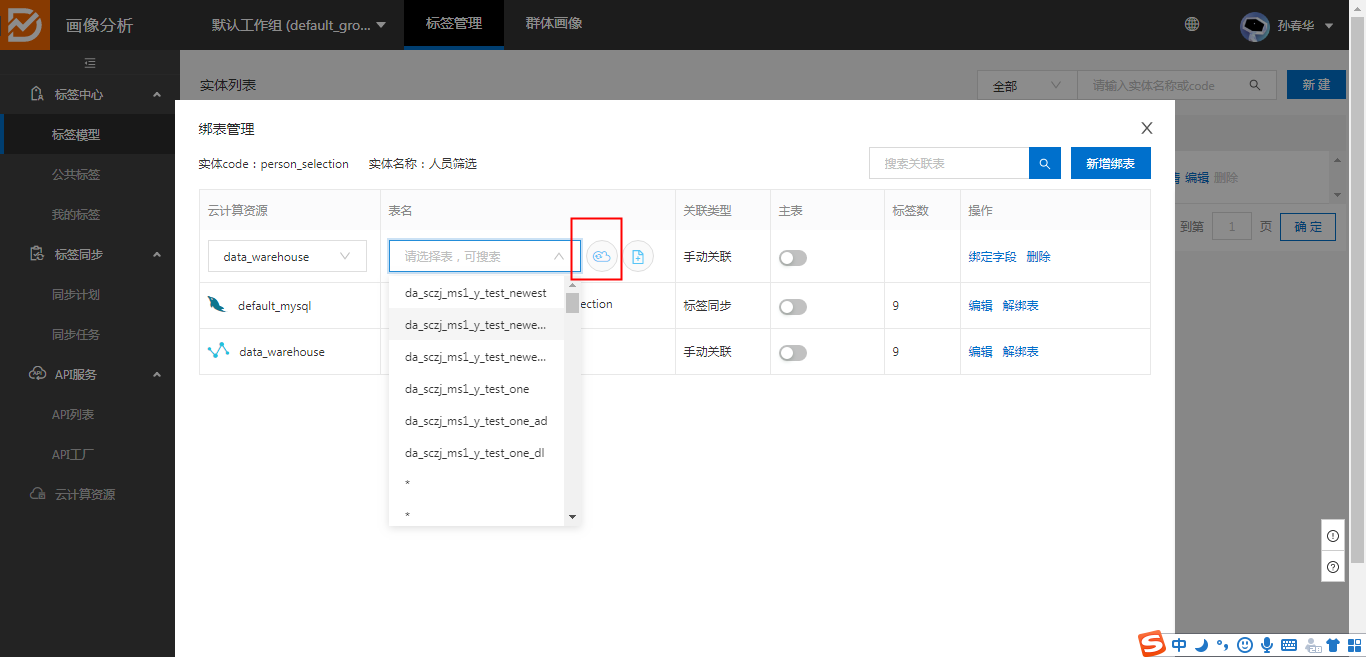
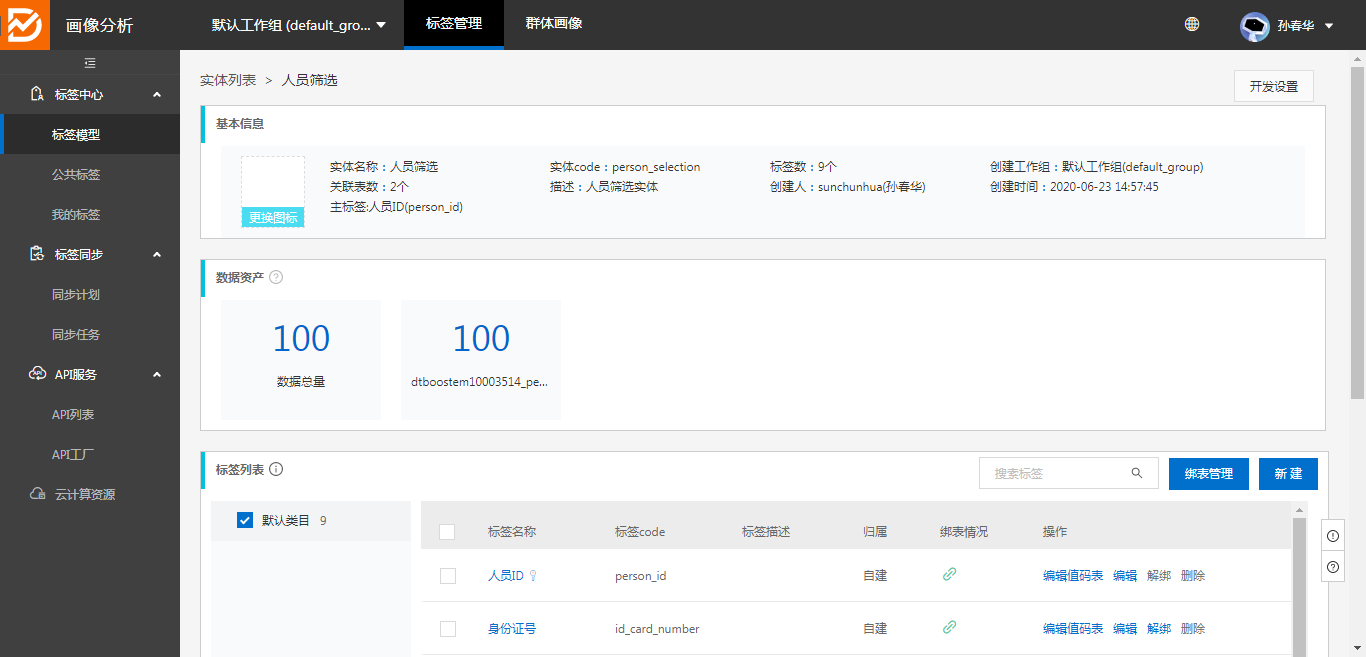
3、选择绑定表后,先点击主字段,绑定为主标签,再绑定所有字段
4、我的标签–快查功能:
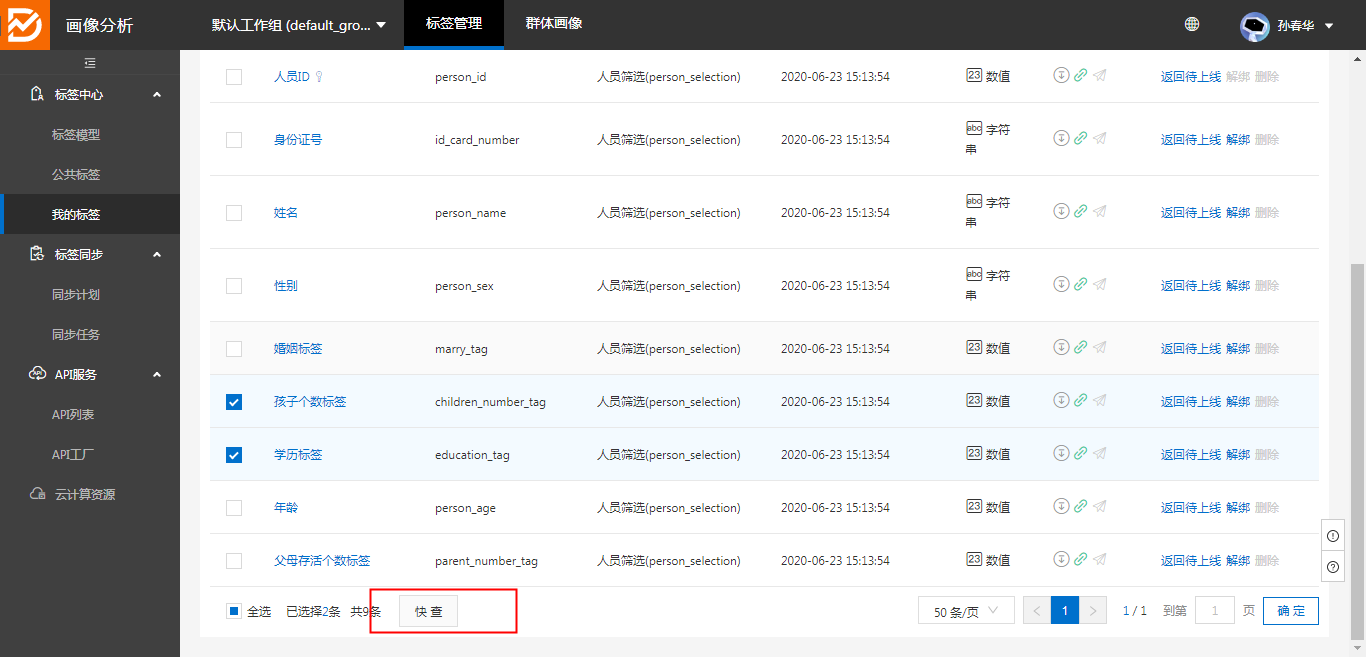
任务同步成功后,才能使用到画像分析的云计算资源分析引擎,对标签数据进行探查与分析:
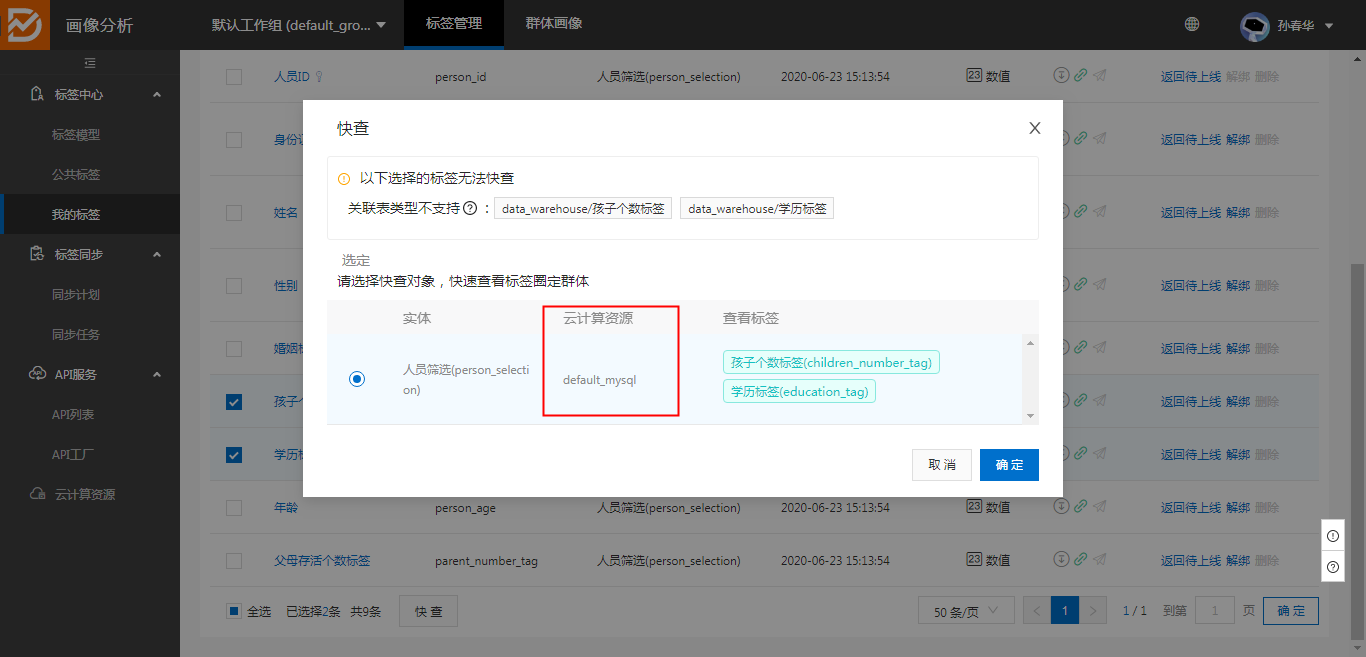
可灵活的选择标签字段,查看数据,通过图表(柱状图、饼图、折线图)展现,数据的聚合(最大、最新、均值、求和、次数)情况
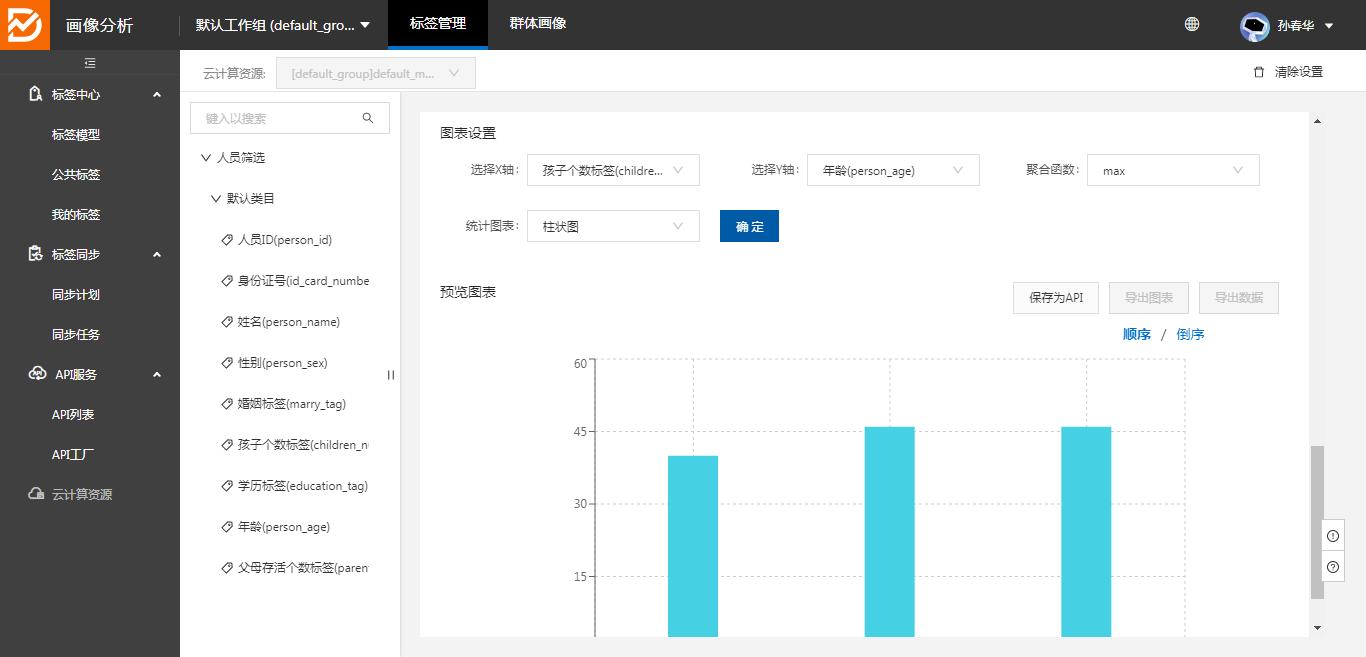
五、标签同步:
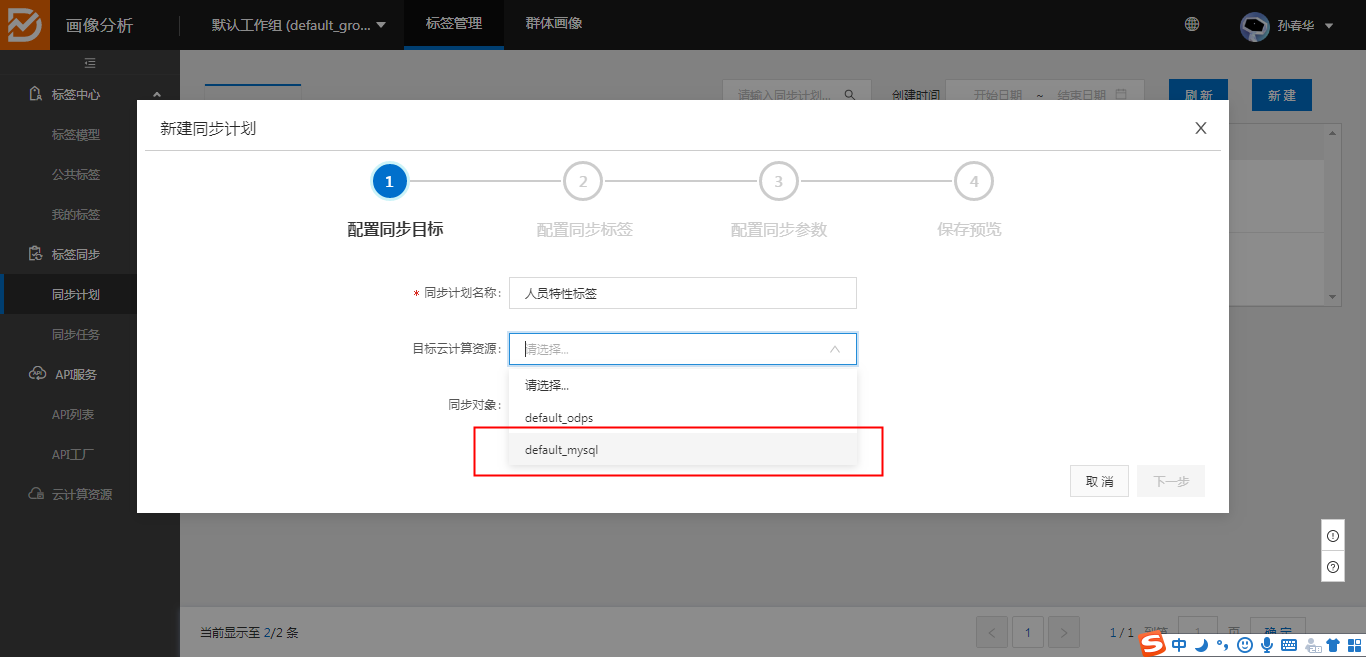
1、配置同步计划:
不能配置已经上线的标签,标签需要先下线,才能配置同步
目标云计算资源需要选择,mysql;选择odps,在群体画像–群体列表中将无法找到云计算资源
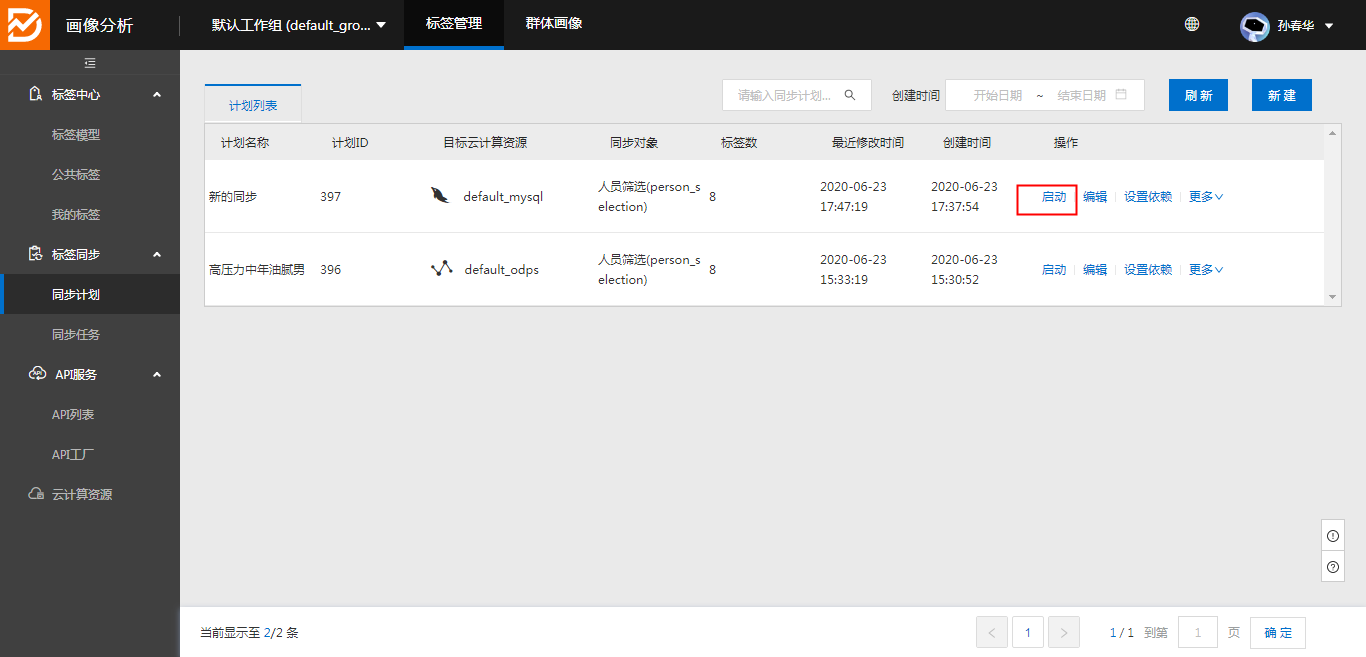
2、同步计划配置完成后点击启动,将数据同步到画像云计算资源中
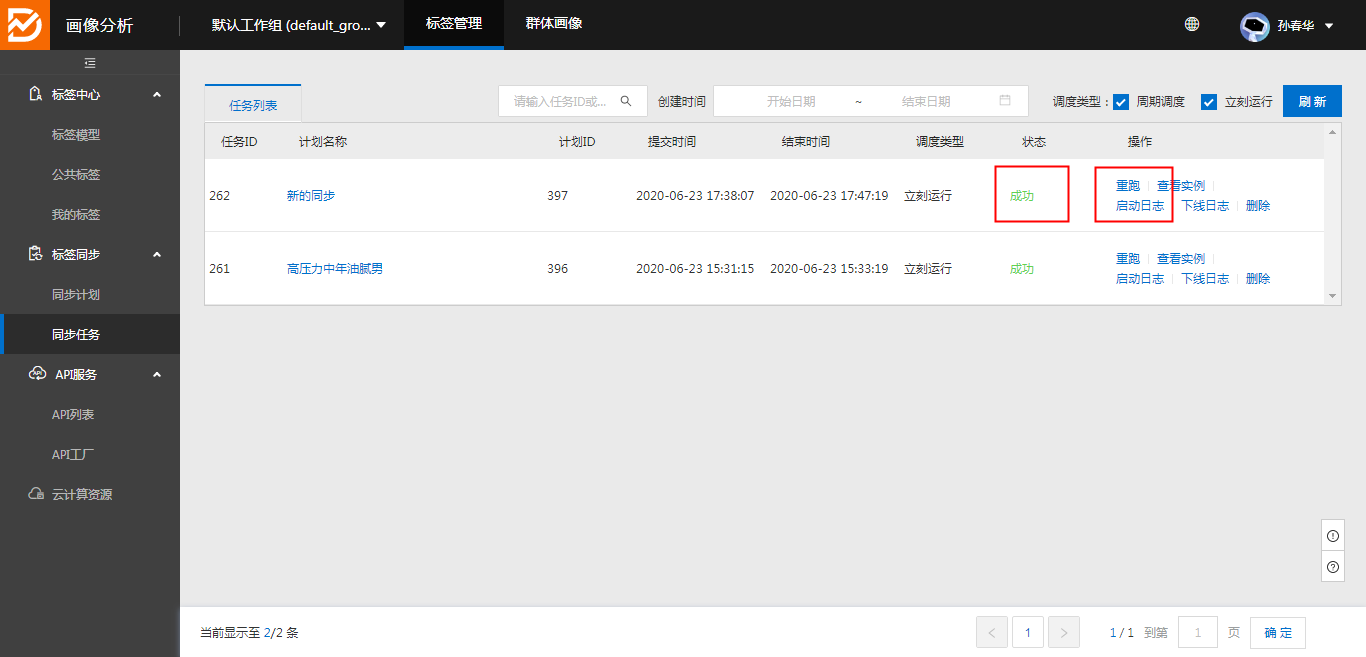
3、可在同步任务中查看同步状态,和进行重跑操作,以及查看错误日志
六、API服务:
与dataworks的数据服务功能类似
画像分析 – 群体画像
七、配置群体:
1、新建群体:
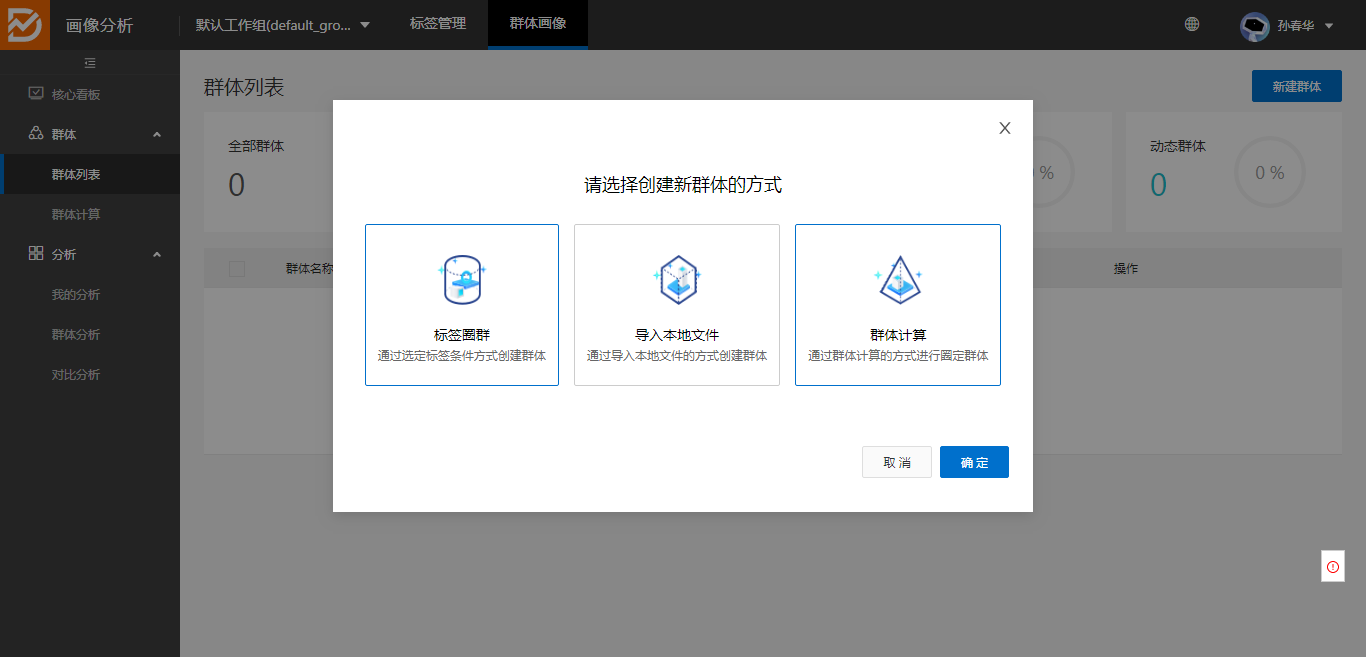
2、选定实体后可以添加标签的逻辑:
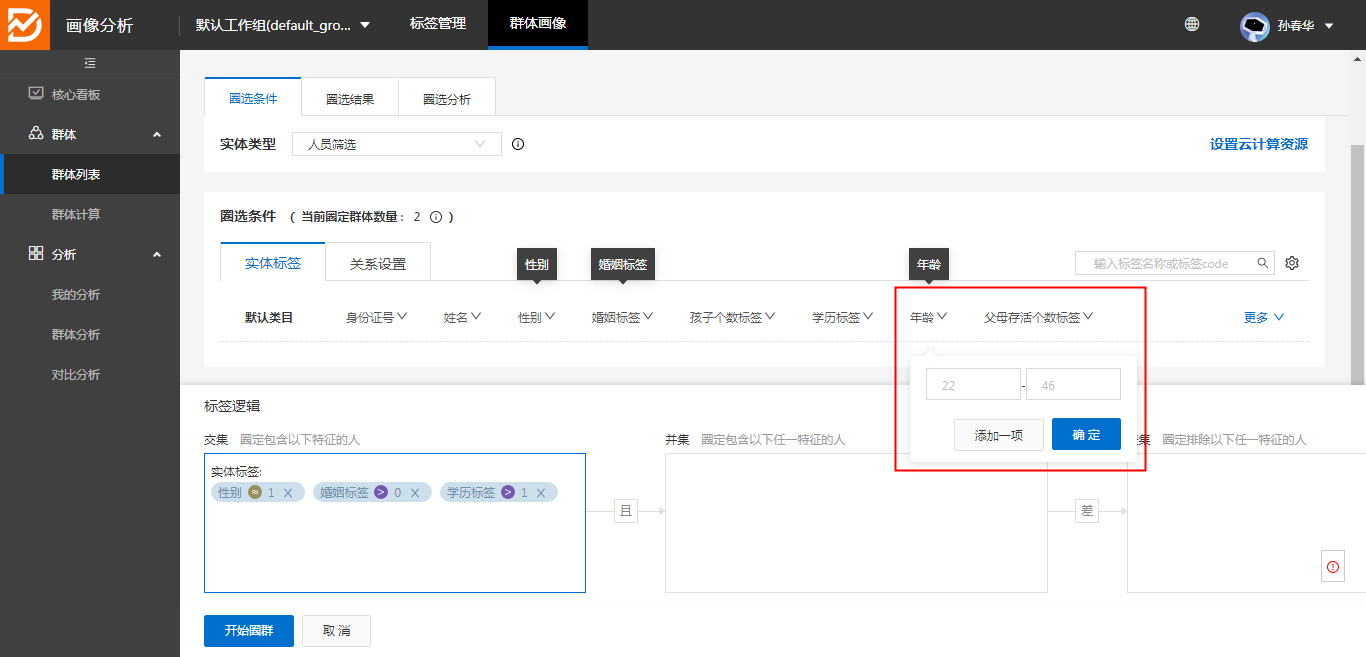
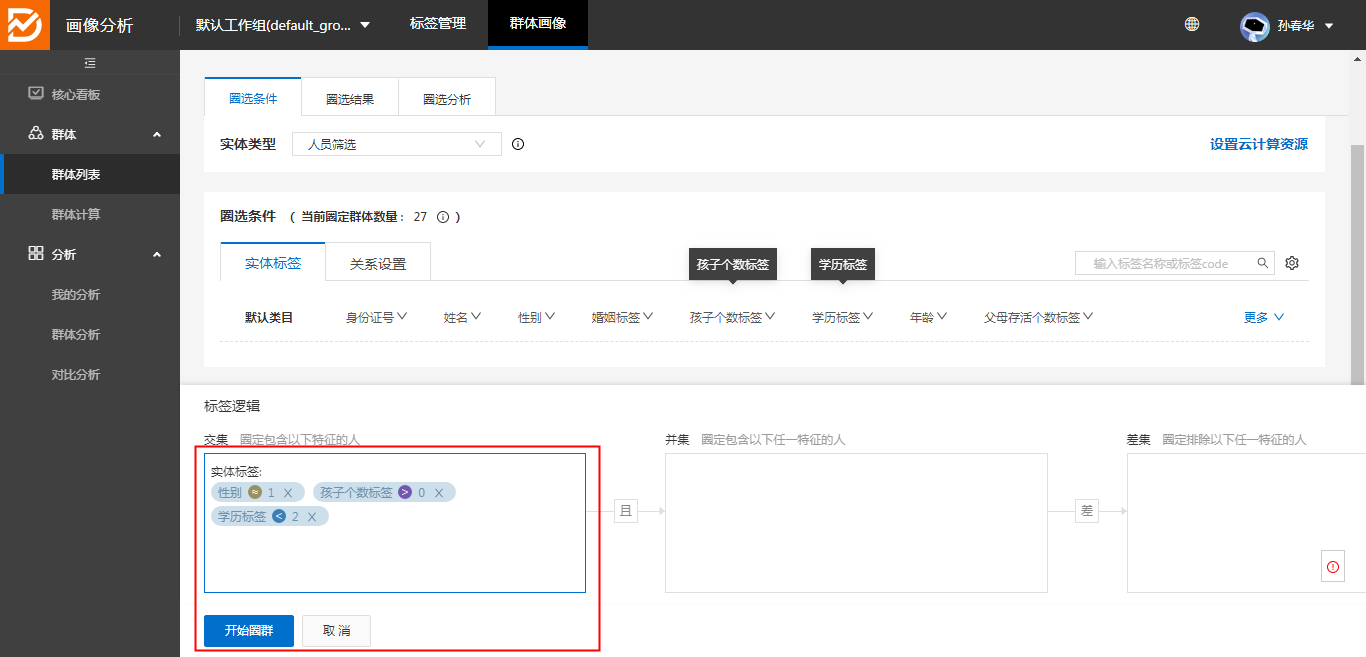
3、目标场景的圈定条件为
1 | 一、中低学历奶爸 |
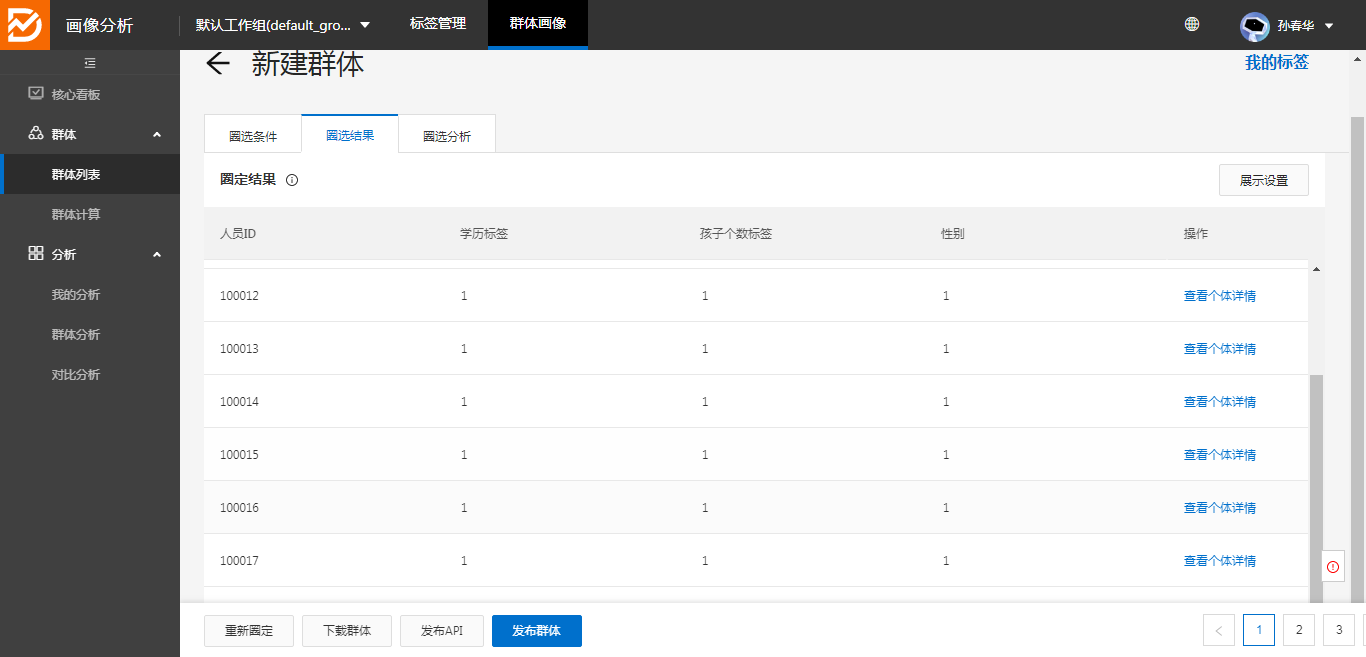
4、圈群完成后,可以查看圈选结果,对结果不满意可以重新圈定,确认结果后必须发布群体,才能生效:
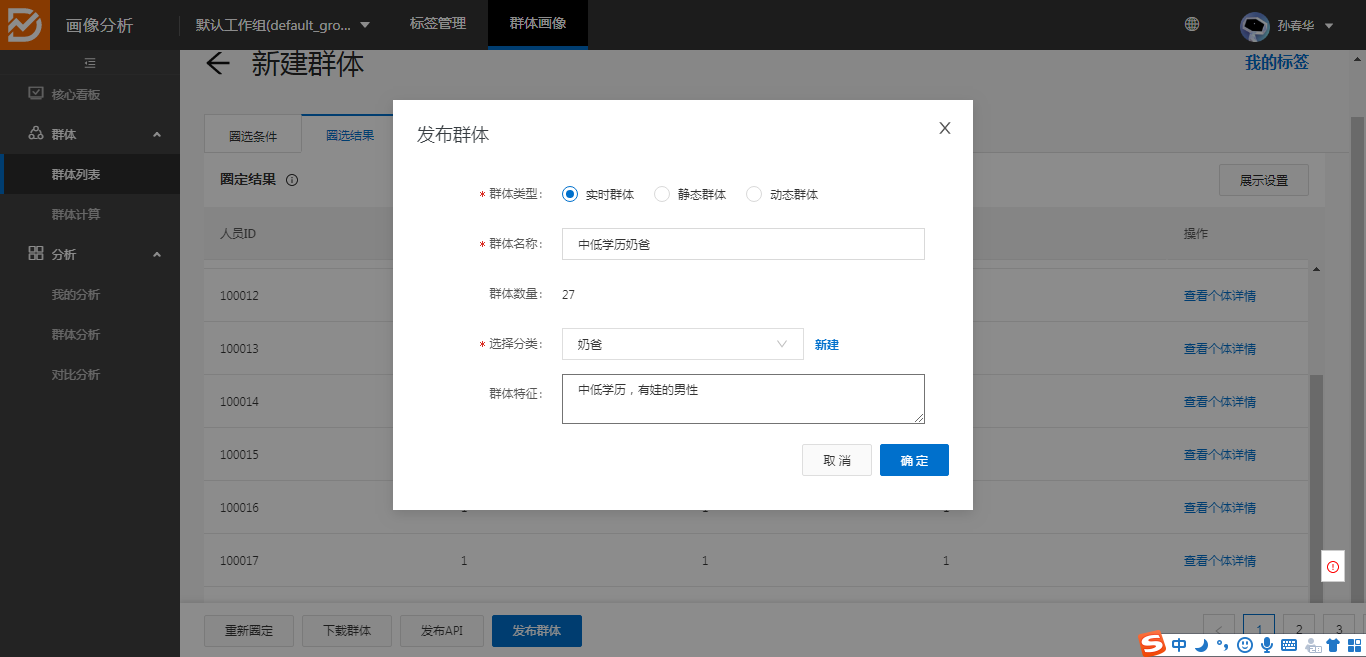
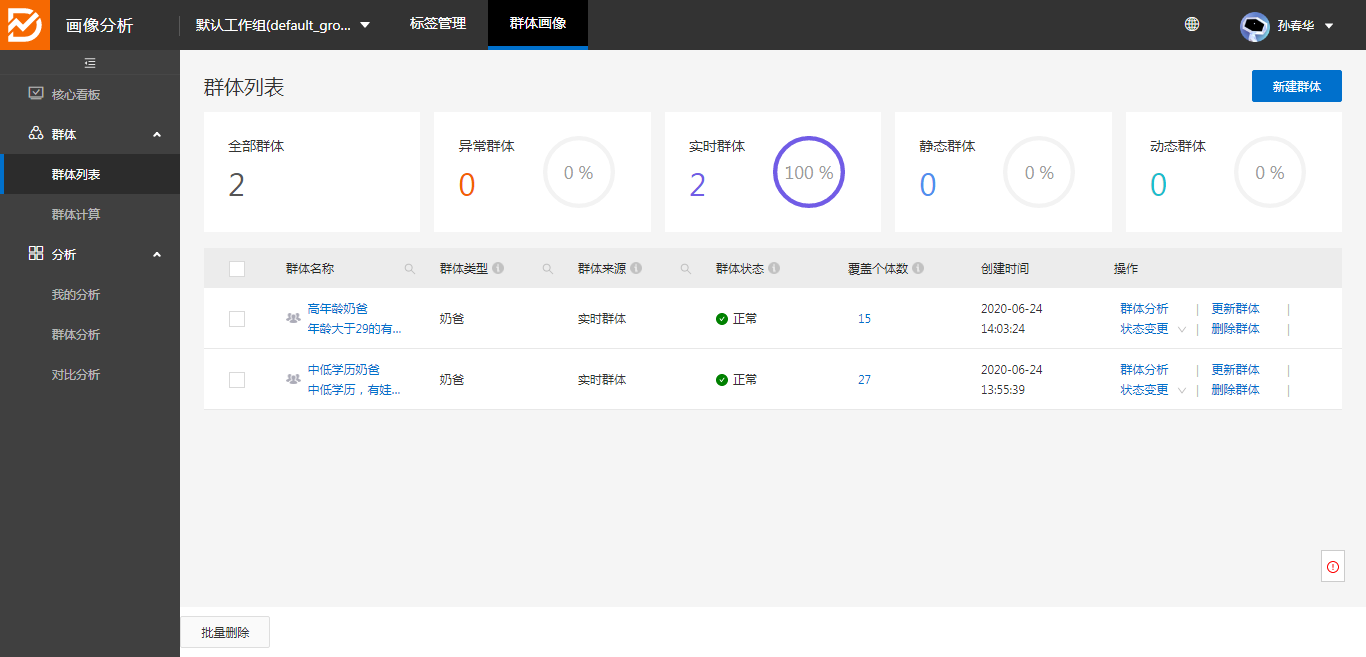
5、发布成功后可以在群体列表中看到发布的群体:
6、群体计算,可以将圈定的群体再次通过(交、并、差)的计算发布成一个全新的群体:
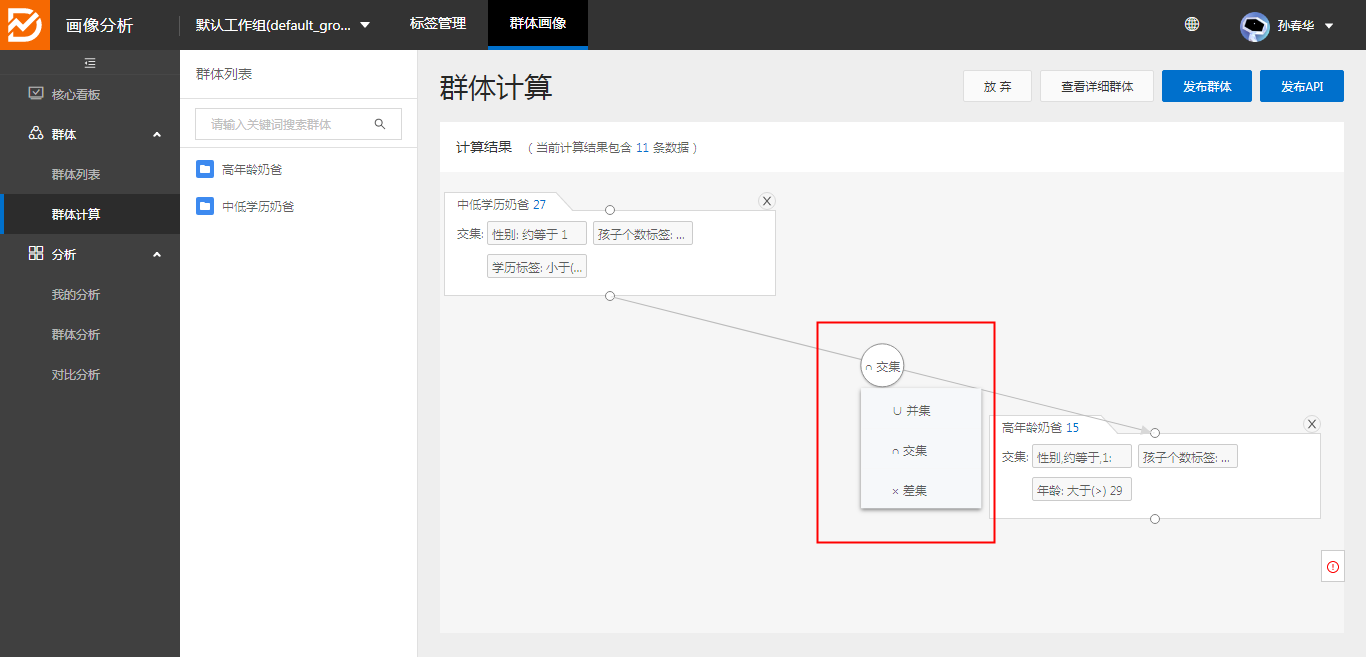
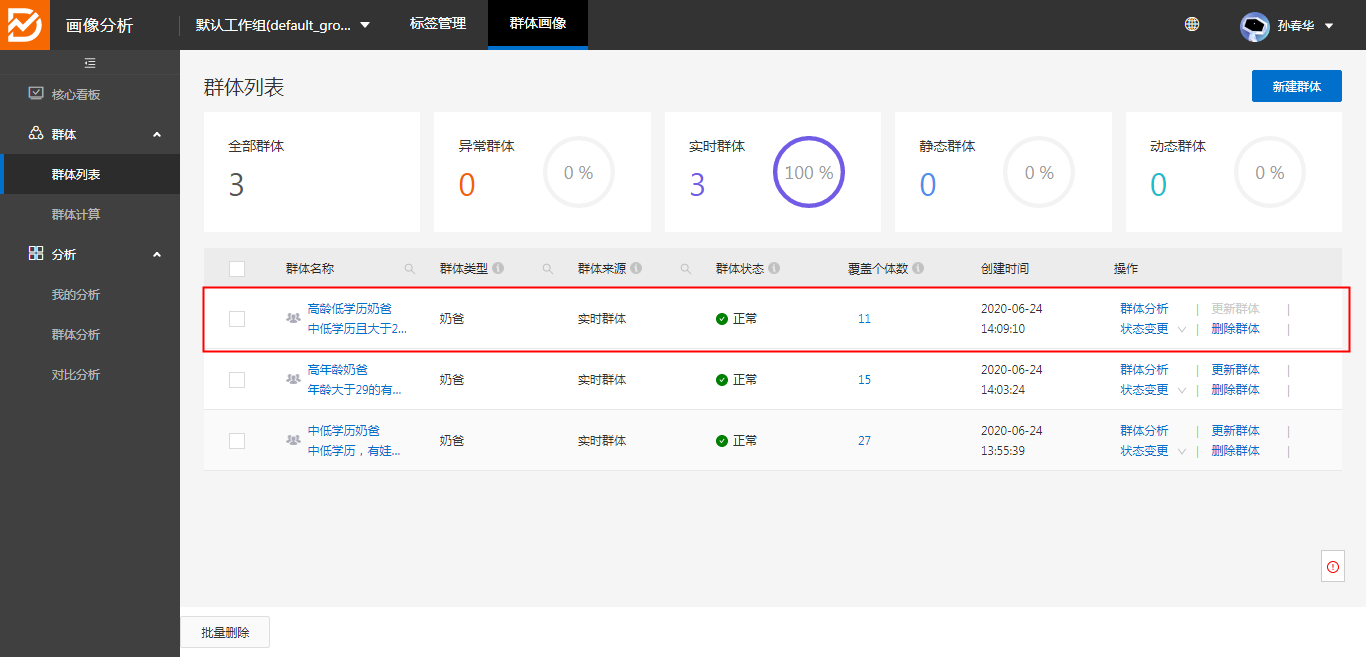
使用交集发布成新的群体“高龄低学历奶爸”:
八、分析:
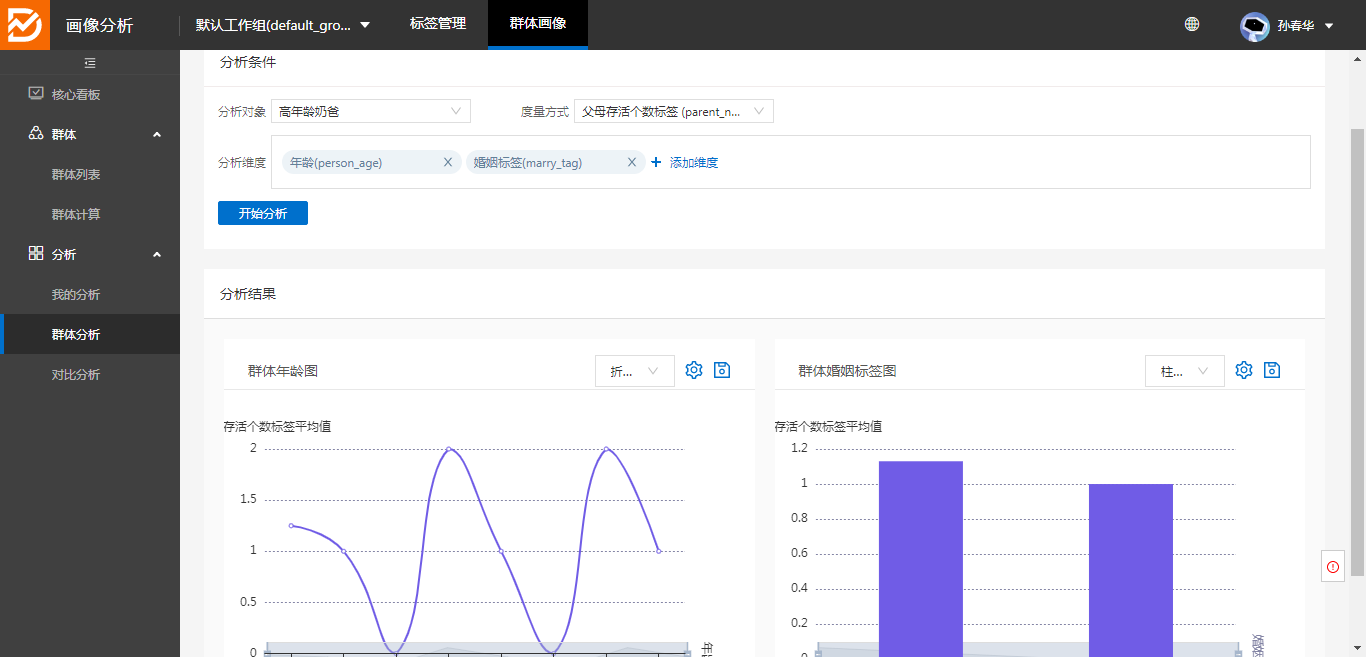
1、群体分析:
选择分析对象(群体)和度量方式,分析维度(每个维度对应一幅图)后,可展现多种类型(柱状图、饼图、折线图、面积图)的图形报表
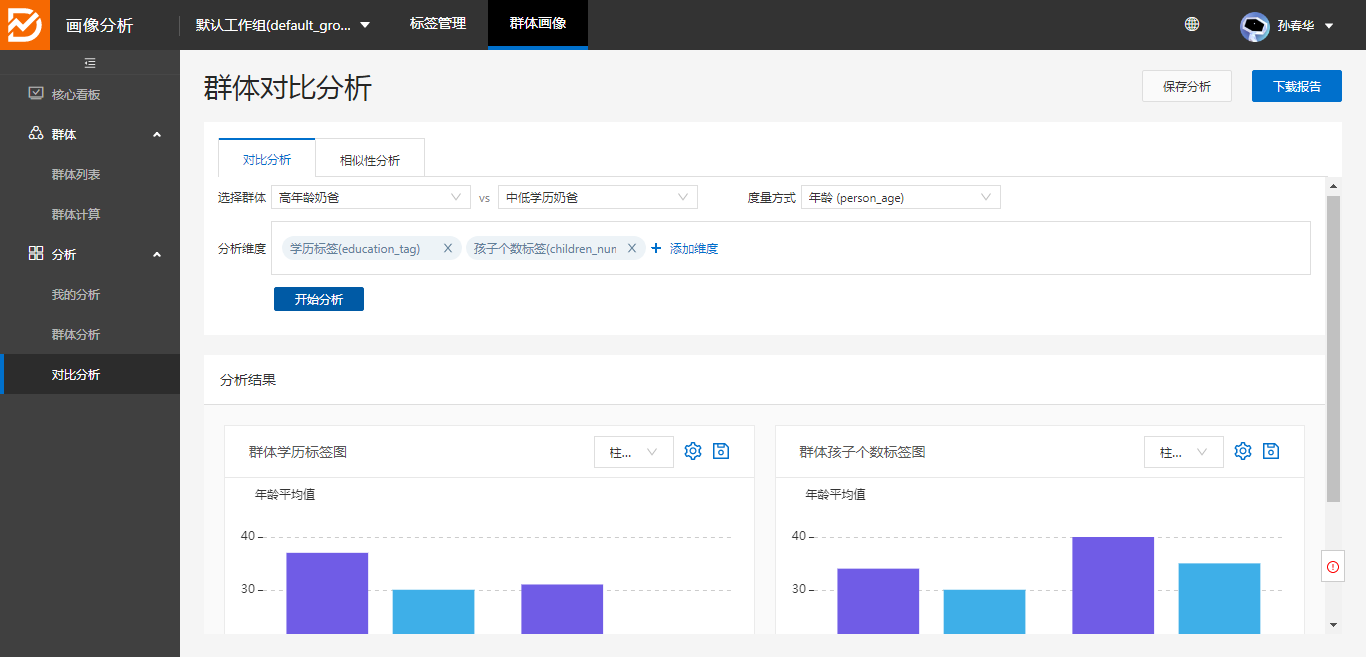
2、对比分析:
对比分析:可以选择两个群体,按照不同的度量方式,选择不同的分析维度,展现不同的图表
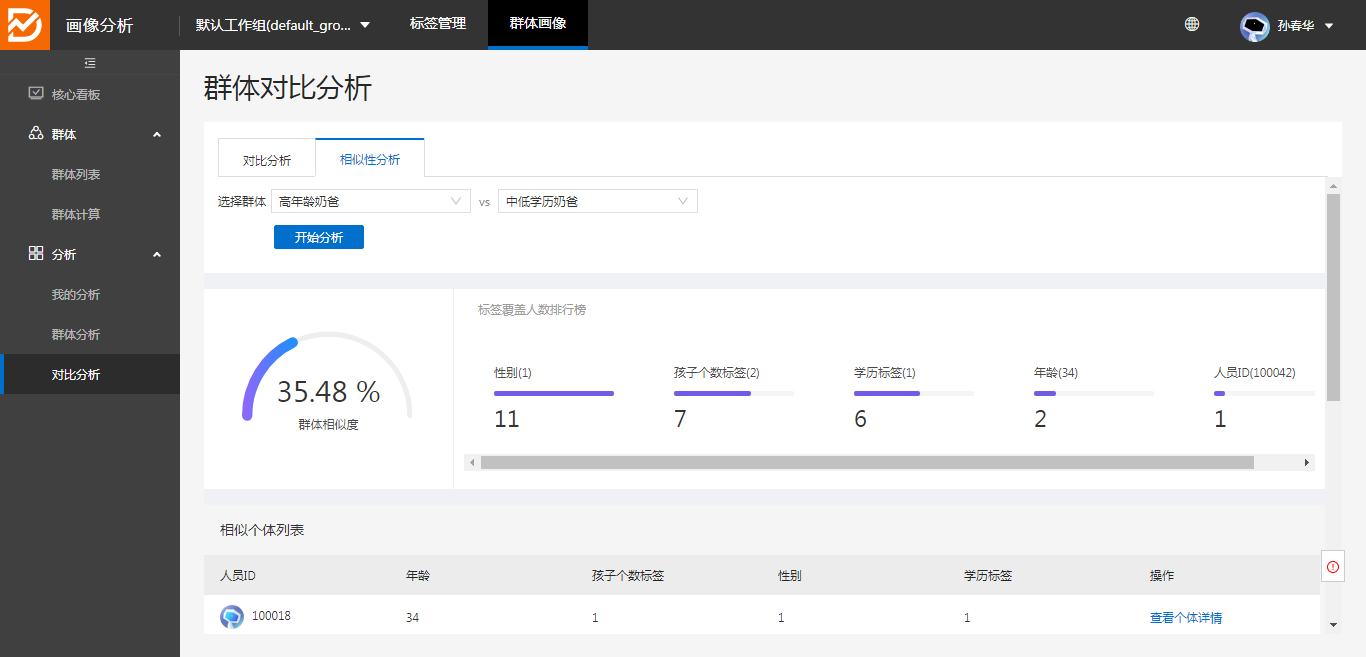
相似性分析:可以查看两个群体的相似度,以及每个标签的覆盖人数
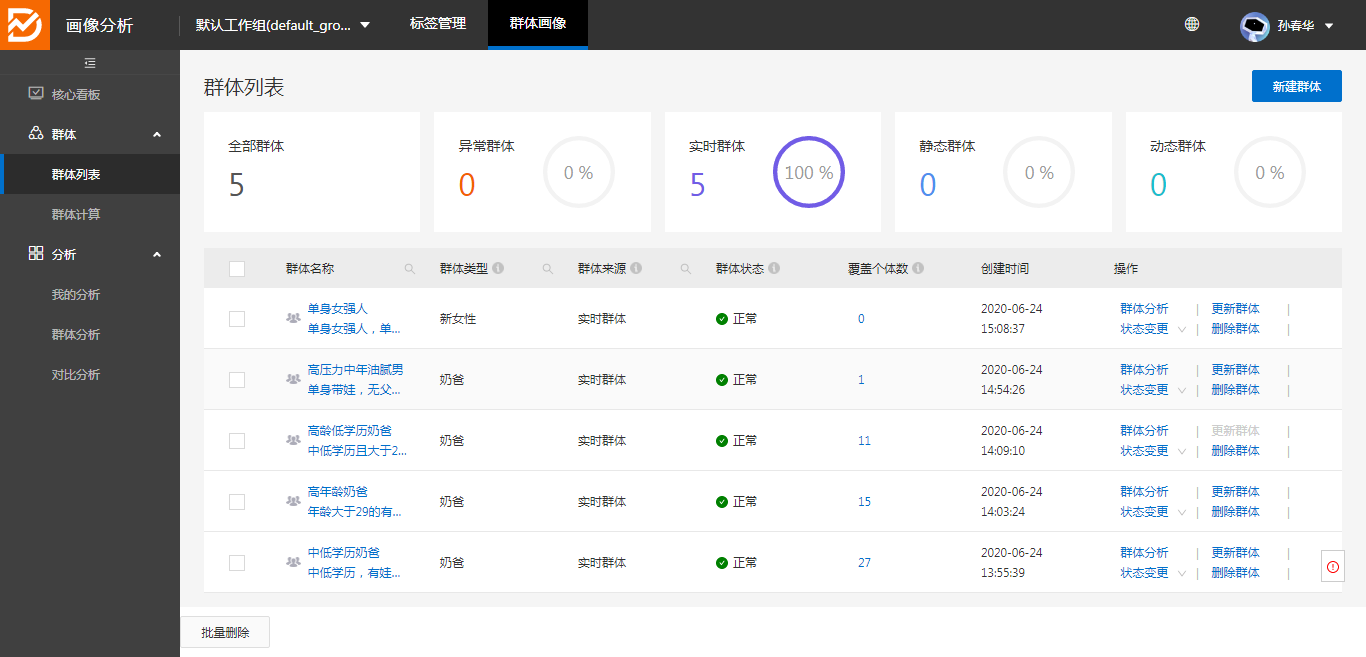
九、全流程体验:
源数据中的样本数据无满足“单身女强人”标签的用户,从源数据中新增一个,然后看出如何同步的画像分析中
1、配置目标群体:
2、源数据中增加一条“单身女强人”用户:
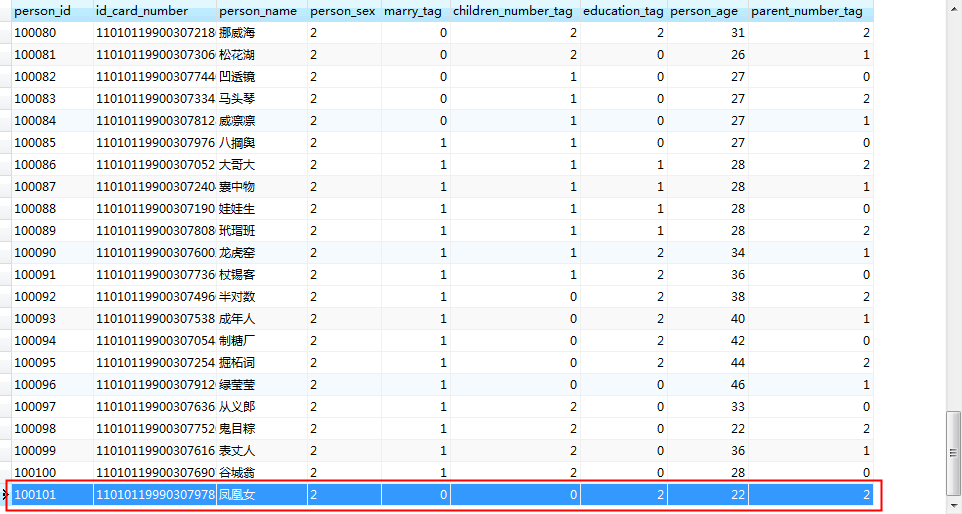
3、执行dataworks同步数据到ODPS中,在运维中心使用重跑调度,重跑成功后日志中显示的记录数位101
4、在同步任务中选择任务,进行重跑调度,重新更新数据。
5、同步任务执行成功后,即可在群体列表中,单击指定群体,看到群体的详情
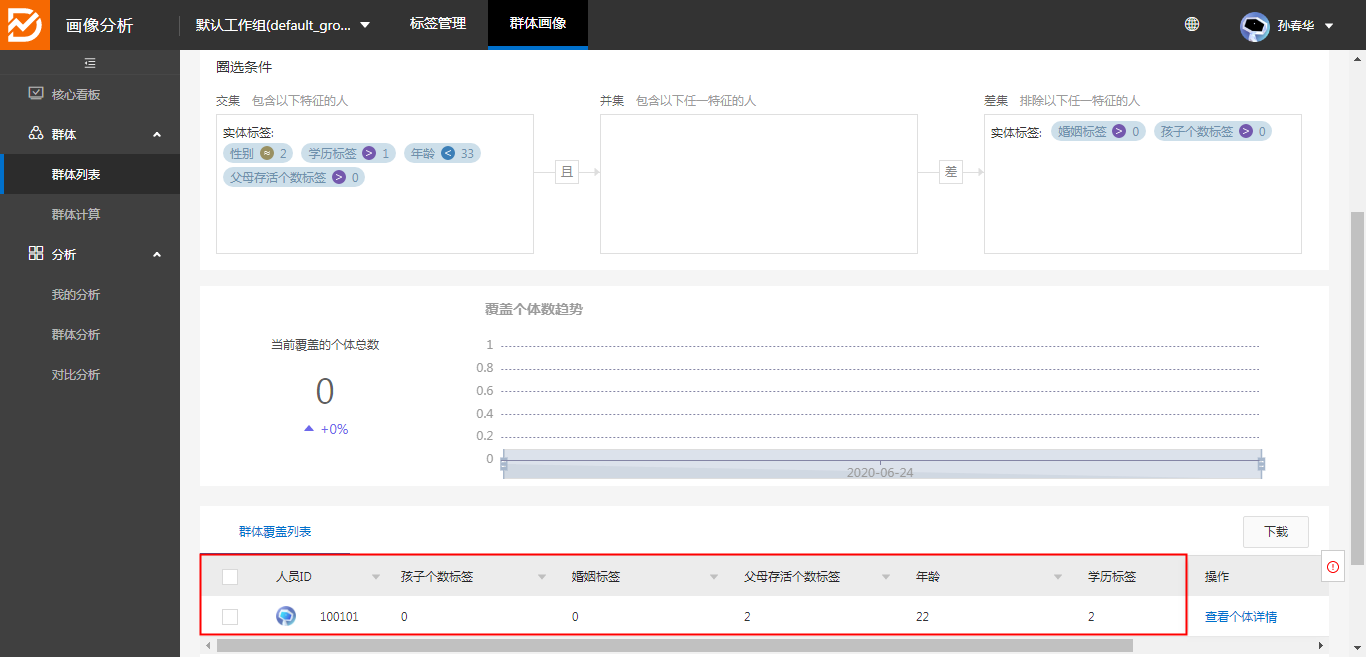
大环节的操作流程:1、修改源数据;2、执行dataworks重跑调度;3、执行画像分析同步任务;4、群体画像中看结果。