neo4j管理模型yEd展现
背景
模型的管理,尤其是模型间血缘的管理,向来是件比较麻烦的事情。
现在就来结合图数据库(neo4j)和图形编辑器(yEd Graph Editor)分享下我自己的经验。
前置准备
要管理模型,必然需要有模型关系;要管理血缘,必然需要有血缘关系;
为了方便维护、多人协同,这里分两个文件,使用xlsx来管理以上的信息
管理模型的model.csv:

name标示结点,relation标示关系,这里只有字段归属表的关系,表不存在关系;
除了这两个字段外,其他字段都可视为结点的属性,使用中可以按需扩展。
管理血缘的relation.csv:
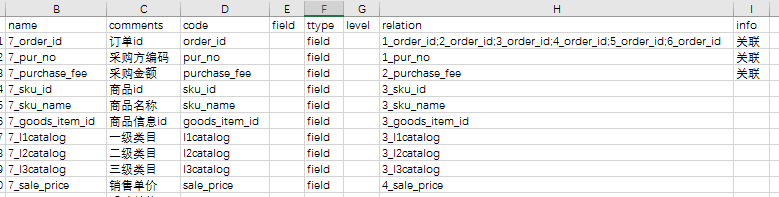
name标示结点,relation标示关系,这里只有字段与字段的依赖关系,不存在依赖关系的结点不用体现;
除了这两个字段外,其他字段都可视为字段与字段间关系的属性,使用中可以按需扩展。
导入neo4j
按照上述文件整理好基本信息后,下一步就是登录neo4j,然后执行脚本将csv文件导入图数据库
1、导入前可先删除已经存在的数据信息
1 | MATCH (r:`统计模型`) |
2、导入管理模型的归属关系
1 | call apoc.load.csv( |
3、导入管理血缘的依赖关系
1 | call apoc.load.csv( |
4、细节优化:
按需增加标签,通过调整标签的大小、颜色可在neo4j中直观的感受出各类结点;表和字段一组,用大小区分;维度和度量一组,用颜色区分;
1 | MATCH (n:`统计模型`) |
5、查询导入后的数据
1 | MATCH (n:`统计模型`) RETURN n |
导出neo4j数据
在neo4j的web界面中查询数据还不大直观,这里可将核心信息导出为json信息,并转化为需要的格式数据
1、从neo4j中导出全量数据
1 | match data=(na:`统计模型`)-[*1..8]->(nb:`统计模型`) |
这里的 id(nb) <> 372 指不导出自动生成的辅助结点,模型中表没有关系,所有数据库自动建立了一个辅助结点连接表。
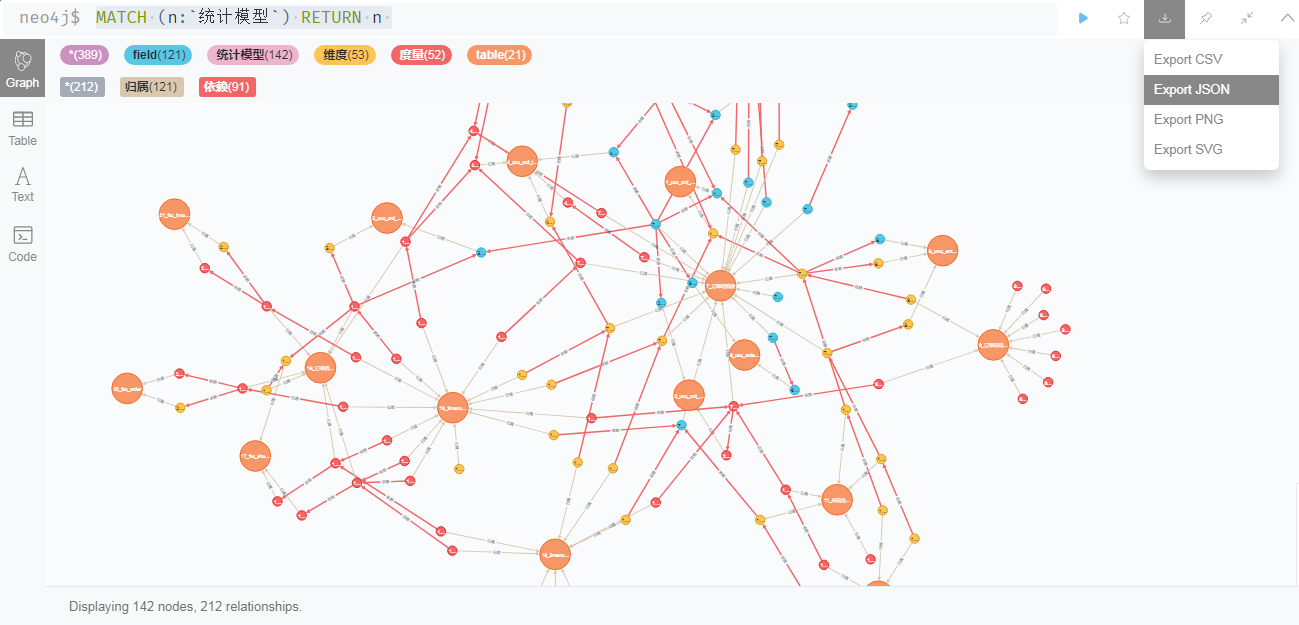
2、导出为JSON文件,并通过 python 转换为csv文件,然后将csv另存为xlsx文件
1 | import json |
yEd导入xlsx文件
1、打开xlsx文件
配置data信息
选择Edge List模式配置边信息 框选边属性,start--end 内容Adopt到 Data Range中 Source IDs 对应 start列 Target IDs 对应 end列 配置节点信息 框选节点属性,Label--Id 内容Adopt到 Data Range中 Node IDs 对应 Id列 Group Node IDs 对应 groupid列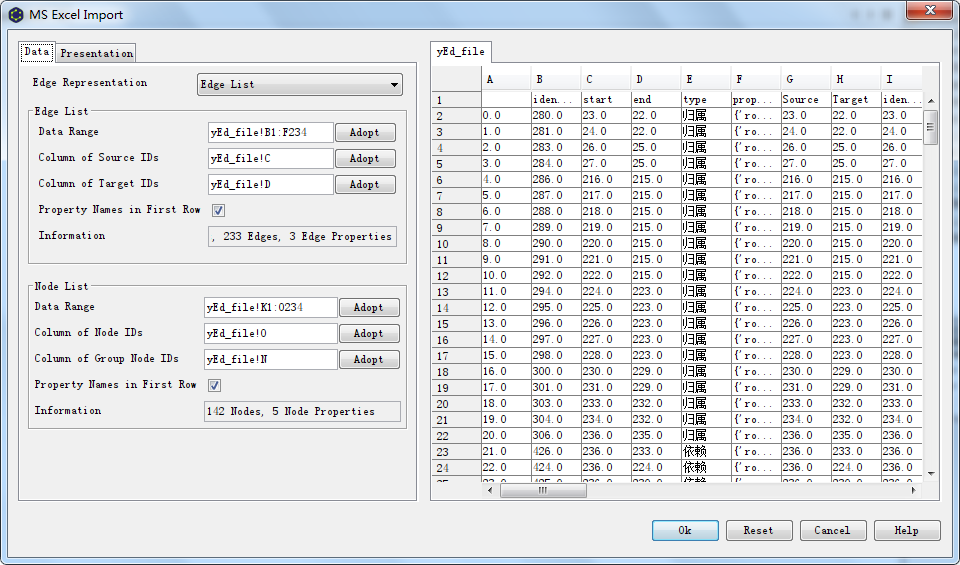
配置presentation信息
配置节点信息 Label Text 对应 comments列 在框选节点属性时选择的列 勾选Fit Size to Label 边框自适应字段长度 配置边信息 Label Text 对应 type列 在框选节点属性时选择的列 Template 选择 Directed Polyline 有向箭头 布局风格 Layout 推荐 Organic模式 <font color='red'> **设置后可以排列为从下往上的布局方式** </font>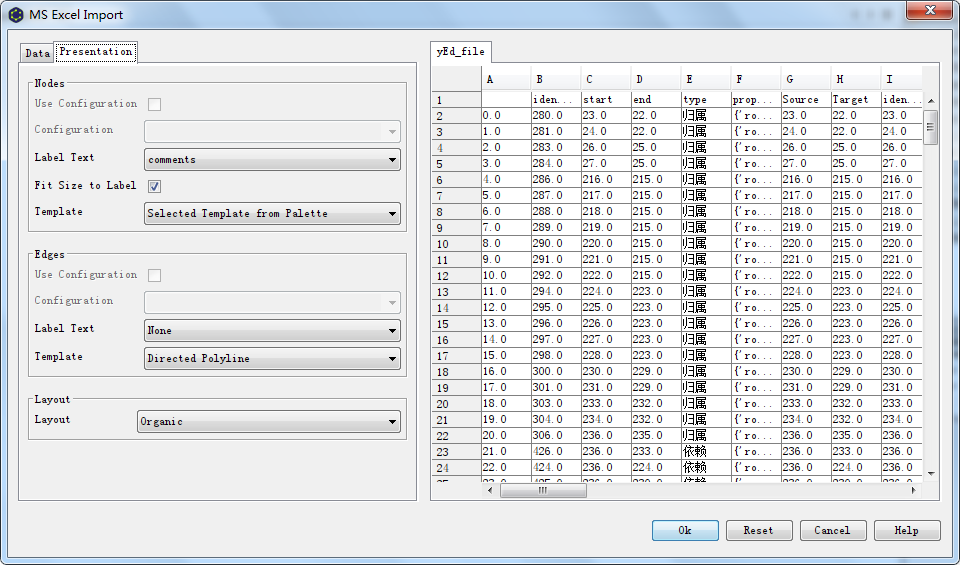
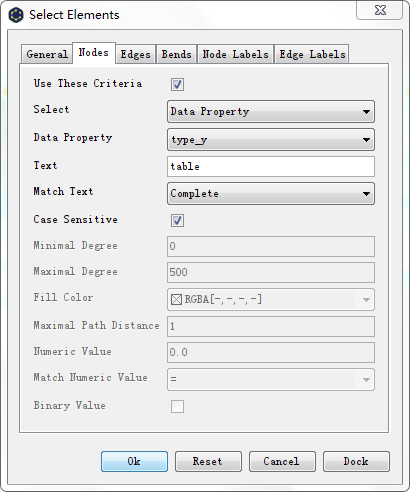
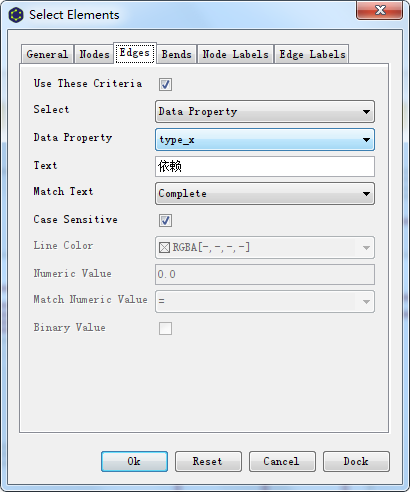
2、细节优化: Tools – Select Elements
- 点击自动布局,进行有序排列
- 选择特定结点,统一修改样式
- 选择特定边,统一修改样式
3、最终效果: